
A couple of hours ago, the Google Security Team posted an article claiming that Google’s made the switch to OpenID, joining Yahoo! and Microsoft in the ranks OpenID providers.
But it looks like someone may have been a bit to hasty to pull that switch (perhaps itching to get some of the limelight Microsoft has been receiving for adding OpenID to all Live ID accounts just the day before yesterday)… because whatever it is that Google has released support for, it sure as hell isn’t OpenID, as they even so kindly point out in their OpenID developer documentation (that media outlets certainly won’t be reading):
- The web application asks the end user to log in by offering a set of log-in options, including Google.
- The user selects the "Sign in with Google" option.
- The web application sends a "discovery" request to Google to get information on the Google authentication endpoint. This is a departure from the process outlined in OpenID 1.0. [Emphasis added]
- Google returns an XRDS document, which contains endpoint address.
- The web application sends a login authentication request to the Google endpoint address.
- This action redirects the user to a Google Federated Login page.
As Google points out, this isn’t OpenID. This is something that Google cooked up that resembles OpenID masquerading as OpenID since that’s what people want to see – and that’s what Microsoft announced just the day before.
It’s not just a “departure” from OpenID, it’s a whole new standard.
With OpenID, the user memorizes a web URI, and provides it to the sites he or she would like to sign in to. The site then POSTs an OpenID request to that URI where the OpenID backend server proceeds to perform the requested authentication.
In Google’s version of the OpenID “standard,” users would enter their @gmail.com email addresses in the OpenID login box on OpenID-enabled sites, who would then detect that a Google email was entered. The server then requests permission from Google to use the OpenID standard in the first place by POSTing an XML document to Google’s “OpenID” servers. If Google decides it’ll accept the request from the server, it’ll return an XML document back to the site in question that contains a link to the actual OpenID URI for the email account in question.
This is shown quite clearly in the following image (courtesy of Google, ironically):
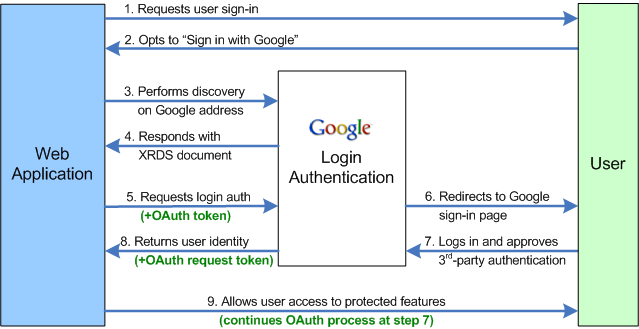
As you can see, steps 3 & 4 are not part of OpenID and leave Google’s implementation of OpenID, such as it is, incompatible with everyone else.
Google actually mentions this in passing:
Starting today, we are providing limited access to an API for an OpenID identity provider that is based on the user experience research of the OpenID community. Websites can now allow Google Account users to login to their website by using the OpenID protocol. We hope the continued evolution of both the technical features of OpenID, as well as the improvements in user experience. will lead to a solution that can be widely deployed for federated login. One of the companies using this new service is www.zoho.com.
Eric Sachs, author of the blog post in question, doesn’t actually come out and say, but he does come very close.
Basically, Google has rewritten OpenID. Not only is it not exactly the same as the current OpenID protocol, it’s so different that existing OpenID relying parties won’t be able to use it. Only a handful of “partner sites” have been updated to understand Google’s perverted version of the OpenID standard, and anyone else hoping to authenticate via “OpenID” to Google’s servers will need to do the same.
But OpenID is an open, community-based standard. Stabbing them in the back by creating an incompatible standard “based on” the same technology and masquerading under the same name isn’t the way to go. Google may have the best interests of decentralized authentication in mind, and perhaps even the better protocol to boot; but this is no way to prove a point.
OpenID is on tenterhooks as it is, and cannot withstand any more efforts to splinter its adoption. Never mind the fact that almost all the big names adopting OpenID are joining only as providers and not as relying parties (rendering the whole basis of OpenID useless) – now even the provider side of things is chaos.
Thanks, Google. Good to see you’re still doing the whole “Do no evil” thing, the community really appreciates this kind of approach to improving de facto standards and pushing decentralized authentication!
Note that OpenID 2.0 is also “a departure from the process outlined in OpenID 1.0”, yet that doesn’t make it bad. I’m not an expert, but what Google is doing looks 99% compatible with OpenID 2.0; of course it would be nice if it was 100%.
Also, usability tests have shown that OpenID does not work. Should Google follow a spec that’s unusable? Or should they evolve and improve the spec? Granted, they should have gone through the community and gotten these changes into OpenID 3.0 before they deployed it.
That’s exactly the point. OpenID has its problems, no doubt about it. But instead of going through the normal channels where everyone gets their fair say about the future of OpenID, Google has released a new standard.. assuming they push it hard enough, they’re pretty much in a position to single-handedly decide shape and control the OpenID protocol, despite the efforts of the community to date.
OpenID isn’t a one-man show, it’s the result of years of joint collaboration and decision-making. It’s not for Google to force their version of OpenID on the world regardless of how brilliant it may be.
Wes: Maybe they shouldn’t have followed the OpenID spec, but it’s hard to see how “ignore parts of the spec yet still advertise it as OpenID” is the correct answer.
Make a new open standard and call it “GoogleID”? OK. Get some guys on the committee and push to make OpenID 3.0 suck less? Great. Implement something new and call it “OpenID”? Not cool.
There’s probably a reason why it’s “on tenterhooks”.
It’s a free market based on demand and supply, and if Google’s changes will finally make the technology popular and convenient to use for both providers and end users, I can only say good luck.
The people should have more priority than concepts, and if one tool does better job than another, it is only fair to let worse tool to die out.
Yeah, maybe egos of individuals that maintain inferior concept will be hurt in the process, but I do not see this as a valid point to portray a competitor as evil.
One of the aspects of “open” is ability of others to improve and progress the technology, which looks like the case here.
Do you have any specific technical objection to Google’s update, which technologically or conceptually inferior to OpenID 1.0?
That’s my .02c
I’d much rather say “use my @mumblemumble.com email address” and let discovery of that godforsaken OpenID URI haven behind the scenes, than have to memorize yet another authentication token.
Single sign-on is supposed to make it easier. Requiring me to memorize the URI of my openid provider is not making it easier. Having my provider perform all the authn for me based on my preferred uid/pwd, that’s easier.
Actually, steps 3 and 4 are very similar to what is done in OpenID 2.0 Rather than using an authentication URL directly, users reference a URL from which an XRDS document can be “discovered.” All Google is doing is changing from “fetch this URL and then look for a link to the XRDS in the HTML” to “query this well-known url with the email address and get an XRDS response.” I agree it’s not OpenID, exactly, but it differs only in its discovery mechanism. There’s no “permission request” stage involved.
I certainly have no gripes with the technical implementation of Google’s protocol, it certainly is easier to follow.. but I’m sure there’s a reason why OpenID didn’t go with an email-based approach in the first place. For one thing, it requires anyone wanting to deploy their own authentication server to use an email address at a domain under their control, which may or not be such an obstacle depending on how you look at it.
“Open” doesn’t mean do whatever you want and use it when it’s protocols we’re talking about. The whole point of “de facto” is that everyone agrees on doing it the same way. It’s no longer an (open) standard if everyone implements it differently.
The idea of OpenID is to decouple who does authentication and where you authenticate for. So let’s give an example why OpenID needs a URL and not your email address. Let’s say you have two email address, one xxx@hotmail.com and one xxx@gmail.com. Now you would like to have one password for both. But if you identify with your hotmail.com address, OpenID would go to hotmail.com for authentication. If you want to check your gmail, you would have to enter your hotmail email address. Of course it’s possible, but a bit strange. So with OpenID, you identify with a URL to an independent OpenID provider, chosen by you, e.g. johndoe.openid.org.
The thing with OpenID is, that nor gmail, not hotmail would control your identity. They don’t own you. This is a good thing for you, but it makes these big corps very uncomfortable. They want to stay in control. This is the reason they all want to be OpenID providers (and own you), but they don’t allow you to login with an OpenID identity registered elsewhere.
Although the concept of OpenID needs a few minutes to sink in, it’s really a good ID 😉
As I understand the developer docs, they say that Google will not be supporting OpenID 1.0, only 2.0. (although perhaps the wording could be clearer) The flow outlined there is pretty much identical to the OpenID flow used by Yahoo.
Except Yahoo! is backwards compatible with OpenID 1.0 and 2.0 – you can use it on any site that supports external OpenID authentication. Same with Microsoft, too.
Would it be possible to create a OpenID proxy for Google? One that understand the Google process but provides a 100% compliant OpenID interface?
Wes Felter, Bryant Cutler:
Yeah, the major difference is that instead of using the URL provided by the user, Google expects the web application to use a specific, hardcoded Google URL. This just wouldn’t scale. Imagine if every site did this – you’d have to hardcode the URL for every provider you wanted users to authenticate from, and either guess which provider they were using from their e-mail address or ask them. (Plus, guessing is in general impossible, due to things like Google for Domains, and asking the user has nasty security implications.)
Basically, this only works as long as you’re only using it with accounts from one provider. This is great for Google, but tramples on the spirit of OpenID. It’s basically just another vendor-lockin authentication scheme a la Microsoft Passport that happens to use OpenID internally.
So what I’m seeing is: other sites can add Google-specific code to let them use Google for authentication. (If you’ve got an OpenID already, nothing changes: Google still doesn’t accept OpenID for any of their services. If you want to use your Google ID as an OpenID with any OpenID service on the internet, you can’t.)
This announcement seems to have zero to do with actual OpenID.
In other words, it’s almost exactly the same as Microsoft’s “embrace, extend, extinguish”, only they’re using the name-brand power of “Google” and “OpenID” to rush past the “embrace” phase. This is simply a way to push GoogleID as a global ID, by borrowing convenient parts of the OpenID spec (and perhaps implementation).
Scalable UI:
Text box to enter User ID.
Combo box to select service provider.
One option in the combo box would be OpenID (i.e. provider information is embedded in the User ID as an OpenID URI).
Others might be things like “Google Account” (which would query google’s API).
Another option would be “other” which would allow you to enter a specific URL to query for the User ID lookup.
As a quality of implementation issue, store a cookie on the machine for commonly used providers (including those entered explicitly through the “Other” option).
Users of “common” OpenID service providers such as Google or Yahoo would be able to just pick them from the list and enter their normal account details. Users of smaller OpenID providers would either use their OpenID URL directly to login (with ‘OpenID’ as the provider), or else use some other identifier and enter their providers directory query URL as needed.
I’m still not seeing a problem here – I’m only seeing a lack of imagination in UI design.
Google is taking advantage of a feature in OpenID 2.0 known as “Directed Identity”. This allows an OpenID 2.0 Relying Party to start the OpenID protocol flow using a known URL (Yahoo!’s is http://openid.yahoo.com/) to allow for “one click” style login dialogues. By performing discovery on this URL, using the XRDS XML format, the OpenID Provider advertises the OpenID Endpoint URL for the Relying Party to make a request against. Google is doing this correctly with the URL to perform discovery against being https://www.google.com/accounts/o8/id.
The piece that Google is currently doing differently is requiring pre-registration of each OpenID Relying Party before users can login to a given site. This does break the common deployment of OpenID on the web today, but Eric Sachs of Google has said on the OpenID mailing list (http://tinyurl.com/562mec) that this is temporary as they work to stabilize their OpenID Provider: “We just need to do the standard scaling, stability, translation quality, etc. evaluation to make sure there are no major problems. If we are lucky, that won’t take much time. However it is more then likely that we will need to tweak things in our user interface to make it easier to understand, and unfortunately translating any such tweaks into 40+ languages takes awhile.”
As for using email addresses as OpenIDs, this is something the OpenID community is talking about quite a bit right now; Google included.
>Frank Booth
>Requiring me to memorize the URI of my openid provider is not making it easier.
I seems pretty easy to memorize http://mywebsite.com or http://myname.myopenid.com or what have you
I don’t see this as a big deal, if Google moves forward and does things to make it more usable. The problem is, that with the exception of Plaxo, Zoho, and perhaps a few others, Google’s OpenID is pretty unusable.
Now, if they gave me the ability to have an OpenID URI something like, http://openid.google.com/aldon.hynes(at)orient-lodge.com then it might be more compelling.
On the other hand, everyone is setting up OpenID providers. I’ve got at least two dozen OpenIDs. The real question is when will more sites, like Google or Microsoft accept OpenID for logins.
As to remembering URIs, I use OpenID delegation, so I only have to remember a simple URI. Also, I’m starting to use the XRIs which work nicely with OpenID 2.0, so I can simply remember an XRI address, which is even simpler.
As soon as I posted about the good news Google was (finally) doing, I was told to look at this article to see that they weren’t doing it right. As soon as I read this article I thought two things:
1) it’s OpenID v2 (not v1 as you suggest)
2) the email login is an extension
… and therefore discarded this ill-written article immediately.
So thanks to David Recordon for giving us the correct facts.
Good post, even considering it was a tad off according to the clarifications given in the latter comments. But still, sounds like Google jumped the gun on 2.0.
Google has been working with the OpenID community, and with other OpenID Providers to ensure that their implementation is compliant. As far as I can tell, Google’s implementation is very similar to Yahoo’s.
The discovery process outlined Step #3 in your post is defined in OpenID 2.0, and is similar to Yahoo’s OpenID Provider. Yahoo (as well as Google and Microsoft) only support OpenID 2.0, and *do not* support OpenID 1.0 or 1.1 because of security and usability issues with older versions of the protocol.
The only variation on OpenID is that Google currently requires that relying parties be on a whitelist. My understanding is that the whitelist is being used because Google’s OP is still being tested, and it makes sense for them to limit their exposure during testing and debugging.
The bottom line is that with one, temporary for testing purposes, exception, Google’s implementation of Open ID 2.0 is 100% compliant. I’m not sure why we should care whether it follows 1.0 anymore than we should care about whether web browsers follow HTML 2.0 standards. If you have a complaint, it’s with the Open ID 2.0 standard itself.
David Recordon: ah, so basically in theory it should be compatible with existing OpenID sites, but in a way that makes normal OpenID implementations look downright user-friendly by comparison. (Of course, this doesn’t apply until Google open it up to everyone.) They really can’t expect every end user to remember such a long and clumsy URL, and indeed they don’t – they expect sites to add special support.
However, I notice that the initial site they’re advertising that allows sign-in via Google OpenID doesn’t accept other OpenIDs, and this seems to be how Google is telling websites to implement it. So basically, we’re going to end up with a load of websites that require either a Google account or a local account for login – not as helpful to OpenID as it could be.
> It?s not just a ?departure? from OpenID, it?s a whole new standard.
How is this a standard? A protocol supported by or compatible with only one company is not a standard, ever.
+1, David Recordan!
Very poor article, spreading FUD (fear, uncertainty, and doubt). Google in fact is a perfectly legit OpenID 2.0 implementation. The email address logging in is a natural fallout of a good OpenID 2.0 RP implementation and works on lots of RPs already for any email provider that also uses the OpenID directed identity feature. No OpenID extension is even required.
Embrace and extend at it’s finest 😉
This essentially makes Google the arbiter of who can and cannot sign in using their credentials on a third party website.
As the article states, this is not “Open” ID. It’s Google seeking control.
Goodness me. Will the anti-Googlists on this thread please read what has already been written?
Google are not fragmenting OpenID, they’re implementing OpenID 2.0 and for a short period while they’re making using their OpenID service more onerous. In the future it won’t work like that.
Sheesh.
In reply to :
“OpenID isn’t a one-man show, it’s the result of years of joint collaboration and decision-making. It’s not for Google to force their version of OpenID on the world regardless of how brilliant it may be.”
I make no comment on the quality of Google’s OpenID vs. the existing OpenID 1.0. But I have to take objection to on a purely conceptual basis. Google’s protocol is evil regardless of how brilliant it might be? The point of progress is to replace older methodologies and technologies with newer ones, precisely (and hopefully) BECAUSE they are more brilliant then their predecessors. Secondly, Google is technically not forcing their vision. The point of Open-Source openness is so that people can code and use and modify what they like. Better implementations get adopted, poorer implementations lose. (Better and Poor here are of course relative to each user). And thus we have a survival of the fittest, or at least, survival of any implementation that brings value to its niche of users. By your admission, OpenID 1.0 seems to be lacking adoption – does that give you a hint about its fitness?
I would say it’s you who is missing the point here.
“Google are not fragmenting OpenID, they’re implementing OpenID 2.0 and for a short period while they’re making using their OpenID service more onerous. In the future it won’t work like that.”
So this protocol that Google is advertising as OpenID really isn’t OpenID, it’s just some interim protocol that they’re pushing while they work on an implementation that actually complies with the standard?
News to me.
fuyuasha, Adam Skinner, Nash, Captain Polaris:
For future reference, David Recordon is the author of the current OpenID Spec. If he says something is a compliant OpenID implementation, and you disagree, please come talk with us on the mailing list.
To the author, whose name I’m sorry I don’t know, you may encourage more productive comments by quoting Recordon. But the part of OpenID which you critique (formerly known as Yadis, now XRI-Resolution) was developed for version 1.1, and improved upon in version 2. I’ve been part of that process since 2005. They are also using an open extension to 2.0, called EAUT, to allow users to type an email address instead of a URL.
These are all open standards. Please, in the future, come join the mailing list and talk with us instead of creating misguided hysteria.
Here’s an explanation of why Google did what they did
http://oauthgoog.blogspot.com/2008/10/googles-openid-idp-is-now-live-for.html
I guess Google is not much interested in following standards other that their own. The certainly consider FriendsConnect as the future of cross platform user experience.
Um…your excerpts above from the Google blog describe OpenID 2.0 rather accurately. What are you complaining about, exactly? Have you read the spec yourself? Discovery is indeed a departure from OpenID 1.0, a departure built into OpenID 2.0.
I’m unable to draw the same conclusion as you when looking at the excerpts of Google’s blog that you have included in your article. Your interpretation doesn’t seem to match up. Google’s own blog says “The initial version of the API will use the OpenID 2.0 protocol to enable websites to validate the identity of a Google Account user” — this is as plain as it gets.
Hello!
Very Interesting post! Thank you for such interesting resource!
PS: Sorry for my bad english, I’v just started to learn this language 😉
See you!
Your, Raiul Baztepo
That has much to do with the difficulty marketing their product as
WeOWNyoushutup 6.0
OpenID seems more pleasant
After years of critisizing Microsoft for not being standards compliant, google now decides to create its own version and call that the standard???
I really dont understand the goal of openid, as it is.
What is the point of having users remember a url plus a username/password at the same time?
the true is that the url is an additional unecessary step. What google made makes sence: users just want to remember username and password and not an additional url. to be able to login into any website with a specific login is the key point (if the site where the user is logging in doens need much info about the user).
That works for Google because the site owners know what OpenID link to redirect to when they their users click the “Google” option ? but what about for Joe Somebody that runs his own OpenID server? Or a new Google competitor still new to the market that wants to run their own OpenID endpoint? You need a URI in there somewhere.
It’s seven years later, and Google is now dropping support for their OpenID 2.0 protocol. It’s going to stab in the back the millions and millions of users who entrusted Google with their login credentials. Some things never change.
@Vote: A most-unfortunate case of “I told you so,” huh?