
 HTTPS is the future and the future is (finally) here. Secure HTTP requests that provide end-to-end encryption between the client making the request and the server providing it with the requested content is finally making some headway, with almost a third of the top one million sites on the internet serving content over SSL, as of August 2017:1
HTTPS is the future and the future is (finally) here. Secure HTTP requests that provide end-to-end encryption between the client making the request and the server providing it with the requested content is finally making some headway, with almost a third of the top one million sites on the internet serving content over SSL, as of August 2017:1
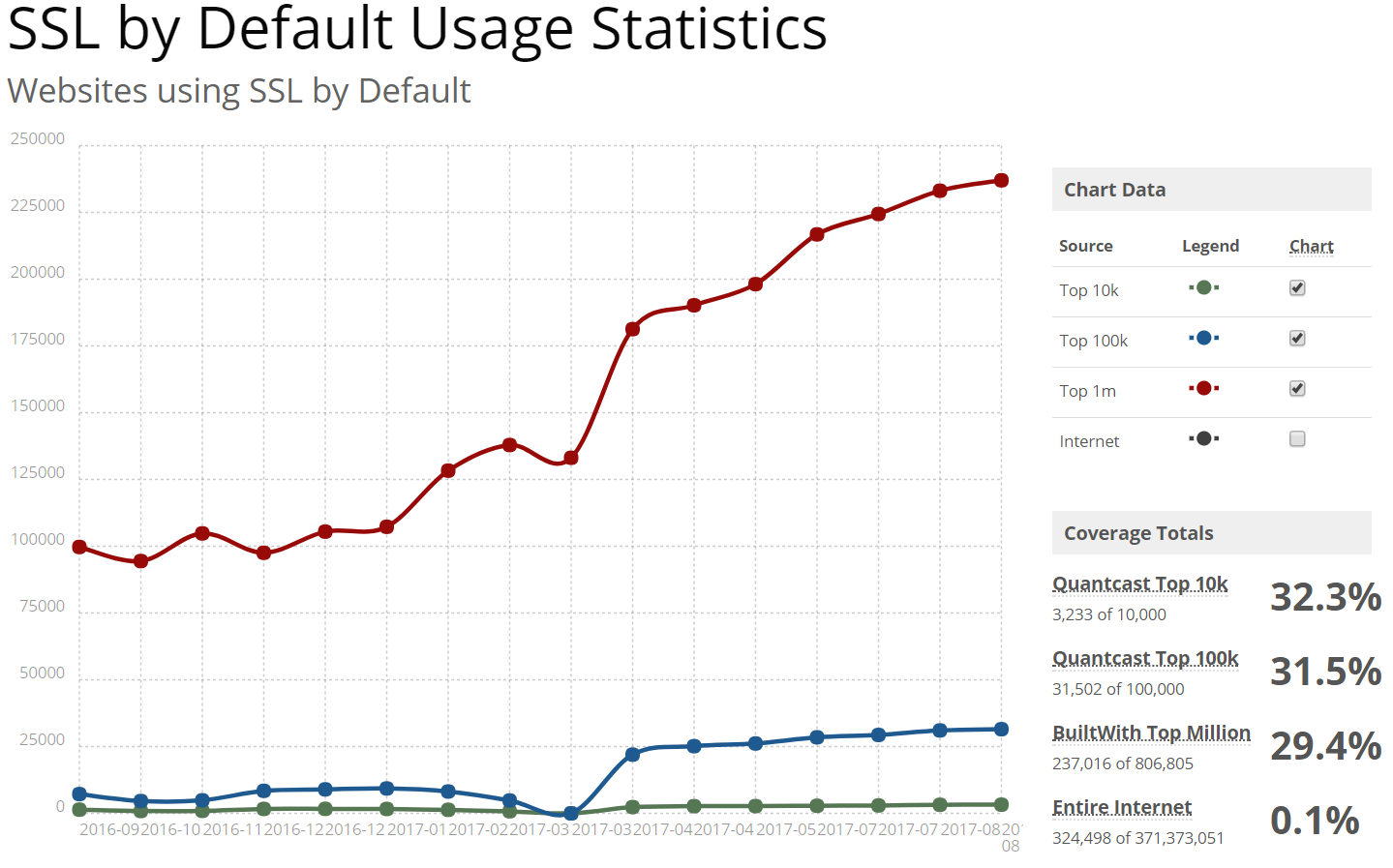
But what this chart doesn’t show is an important subsection of HTTP traffic that is unfortunately infamous for a general lack of security: IoT. The “internet of things,” as it is called, is famous for fiascoes that have allowed hackers to break into the privacy of homes, spying on consumers via internet-enabled nanny cams, gaining access to so-called “smart locks” to break into houses, obtaining sensitive information, and exposing private content and data thanks to insecurely designed consumer products and services that live on the local network.
This segment of “web” traffic has long been plagued by insecure defaults and abysmally poor (in)security practices that can best be summarized as “non-existent” that have lead to countless recalls, security leaks, and more in the past ten years – a trend that will likely only continue at an even more alarming rate as IoT devices become cheaper and more prevalent with today’s gadget-hungry consumers.
There’s so much that’s wrong when it comes to security in the home that we should really be doing whatever we can to encourage better security practices – not, as the major browser vendors have taken to doing, punishing those that attempt to adopt better security. Because that’s the current state of affairs when it comes to providing SSL-encrypted HTTPS for configuration pages, live streaming feeds, etc. served up by IoT resources on the local network.
The problem that we’re talking about is the fact that if a device on your network, identified by its IP address falling in the range of reserved IP addresses per RFC1918 (for example, everyone’s favorite 192.168.1.1 or the corporate-preferred 10.0.0.1), all major browsers will throw up a scary looking warning page telling you that the site you’re trying to visit is not to be trusted, here be monsters, proceed at your own risk, and beware of hackers trying to steal your potatoes.
Here’s what trying to access an HTTPS secured web page on the local internet that responds with a self-signed certificate with its IP address as the common name looks like in Chrome, Firefox, Internet Explorer, Edge, and Safari:
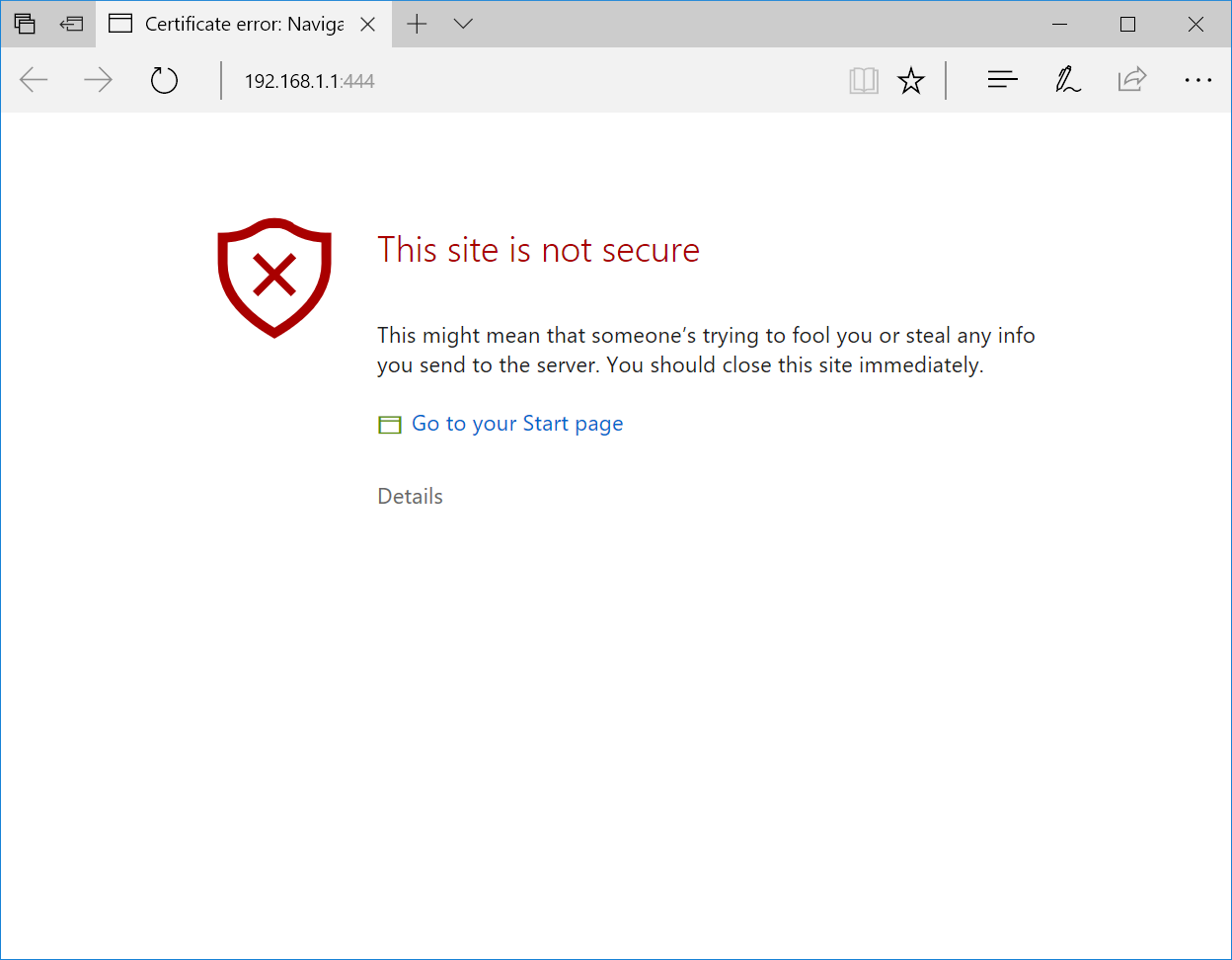
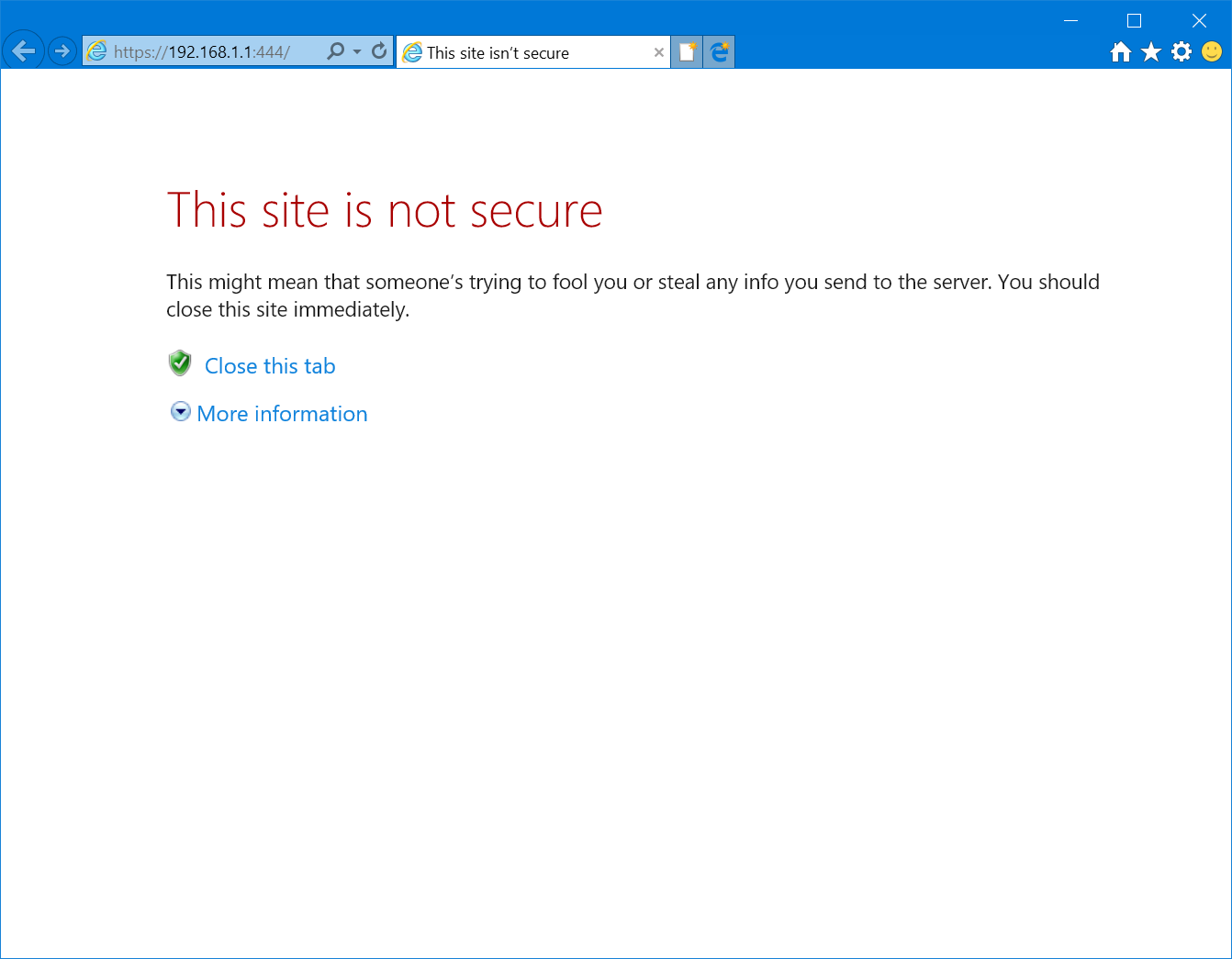
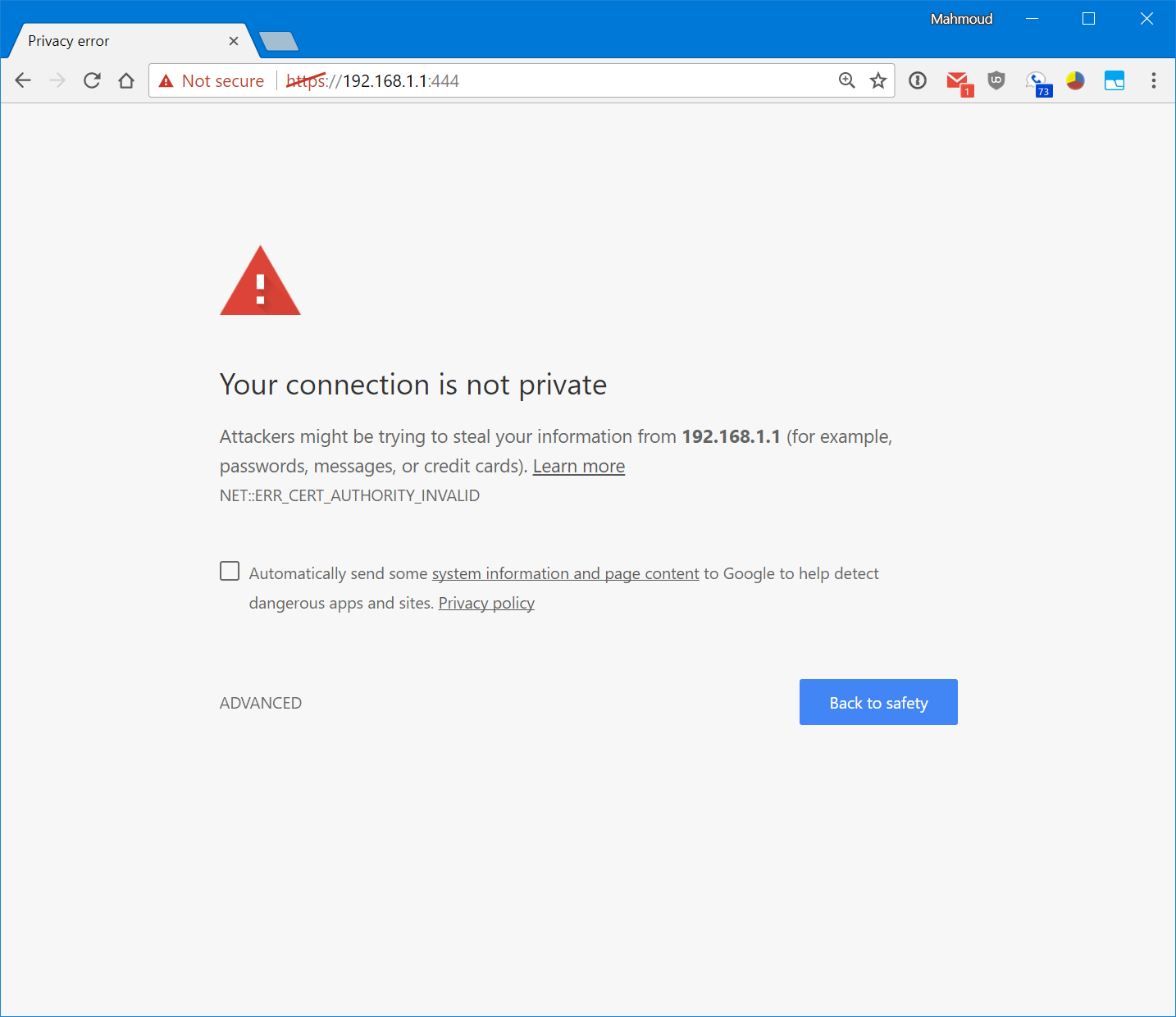
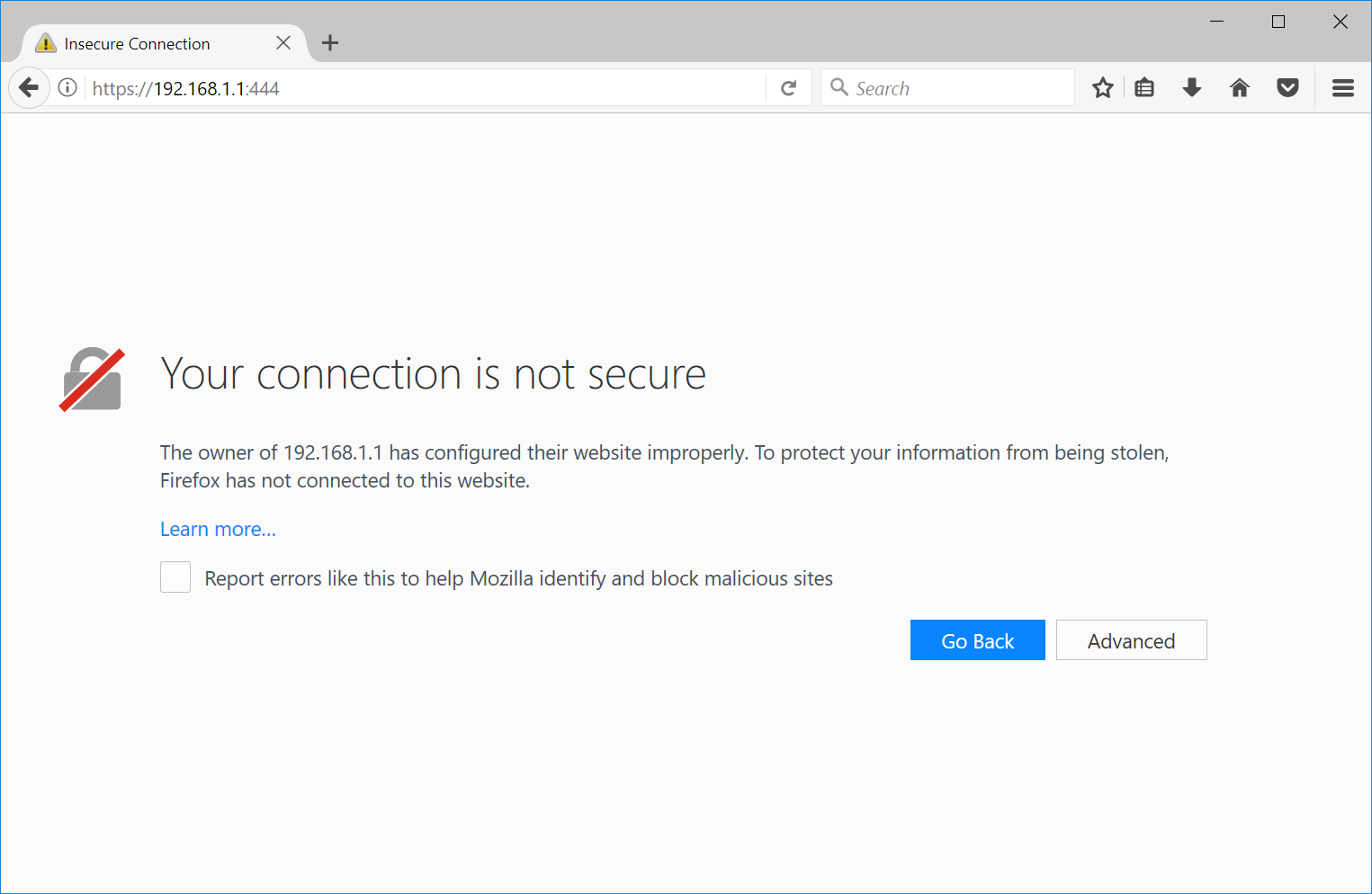
What do you see? Red. Lots of it. Warning. Blood. Death.2
The scary red warnings aside and the horrible user experience of an interstitial aside, of all the browsers in question, only Firefox doesn’t use scare mongering in the text, and instead of warning you that hackers are trying to steal your unborn children, it merely suggests that perhaps the owner of 192.168.1.1 has configured their website improperly.
The problem is that all these dialogs (yes, even Firefox’s) are just plain wrong. Not just annoying and unnecessary but outright wrong.
As of January 1, 2013, the official orders from the CA/B forum (an organization formed of browser and certificate vendors to promote security on the web) were to no longer issue certificates for RFC1918 IP addresses and other local resources that expire past November 1, 2015 – and to forcefully revoke any non-expired certificates that remained valid past October 2016.
Certificate authority Digicert sums up best the list of resources that are affected:
- Any server name with a non-public domain name suffix. For example,
www.contoso.localorserver1.contoso.internal. - NetBIOS names or short hostnames, anything without a public domain. For example,
Web1,ExchCAS1, orFrodo. - Any IPv4 address in the RFC 1918 range.
- Any IPv6 address in the RFC 4193 range.
Basically, it’s literally not possible to get a security certificate signed by one of the trusted certificate authorities (which is the metric your browser currently uses to determine if it should show a scary warning or let the request through unscathed).
Additionally, one of the biggest benefits of HTTPS is that it protects against the very effective DNS spoofing attack, wherein any attacker can throw up a hotspot that can direct you to a fake page hosted on a server under their control that pretends to be the site you requested – intercepting any data you submit – all the while your address bar still reads http://facebook.com/ or http://nuclearcodes.gov/
But this entire class of attacks doesn’t apply when requesting resources by IP. There’s no DNS involved, and by definition, these addresses are “network specific” – i.e. 192.168.1.1 when you’re on one network is a different 192.168.1.1 than when you’re on another. In other words, the “attack” that your browser is trying to protect you against (one server pretending to be another) is actually how IP addresses in the RFC1918 range were designed to work.
What makes this particularly bad is that these same browsers won’t show you this scary warning if you try to visit such a page over plain, old HTTP:
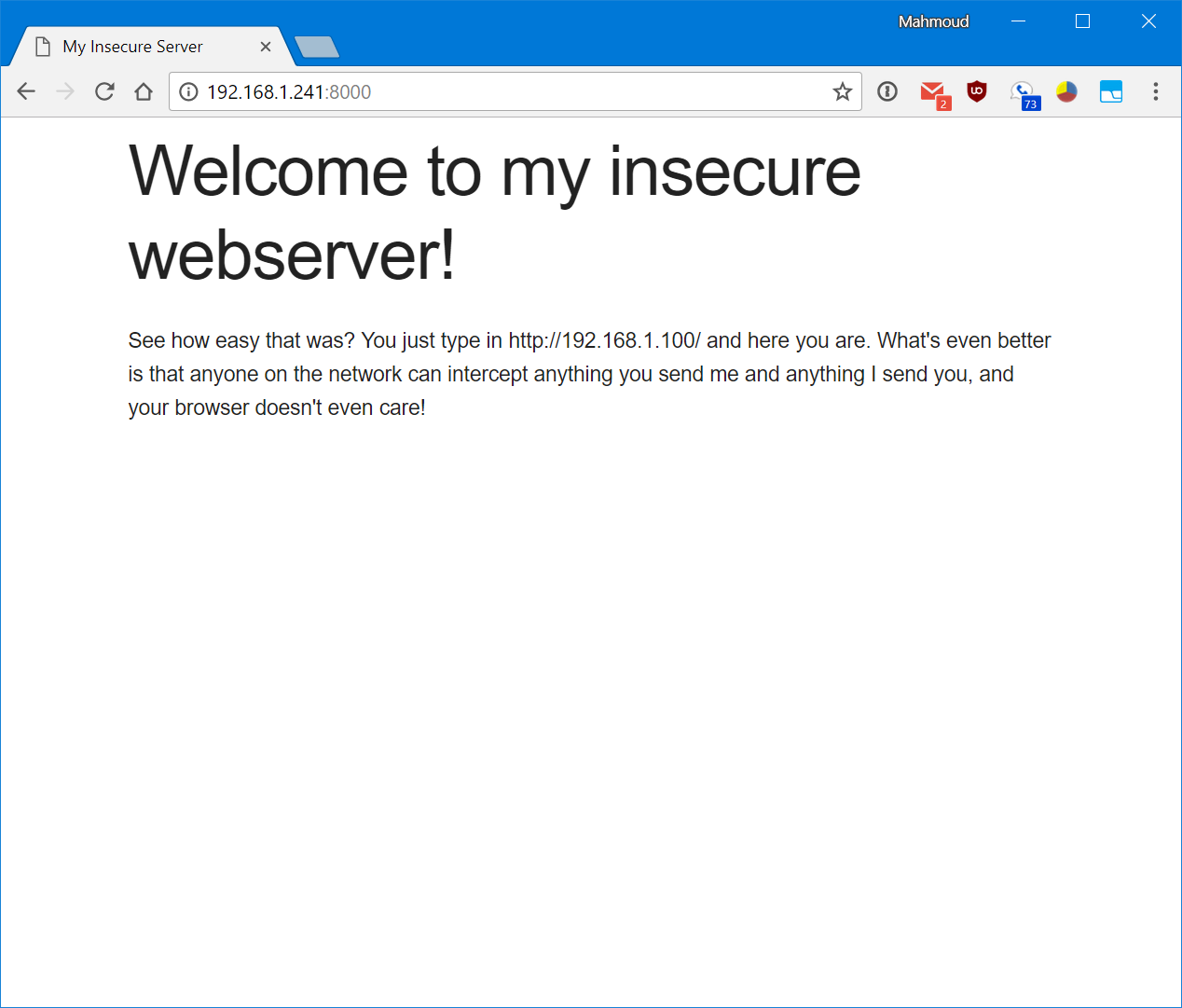
There’s not much to see – it’s just a normal web page served over HTTP with no scary warnings, no red exclamation marks, no hidden “click here to continue at your own risk” links. Just the page you requested, as it was meant to be shown.
While there are proposals to mark HTTP (aka actually insecure) content as insecure by default in future versions of major browsers (here’s the link to the details for Chrome), this does not extend past including a small (not red) info message in the address bar that only appears when the user is filling out a form on the site in question, like this:
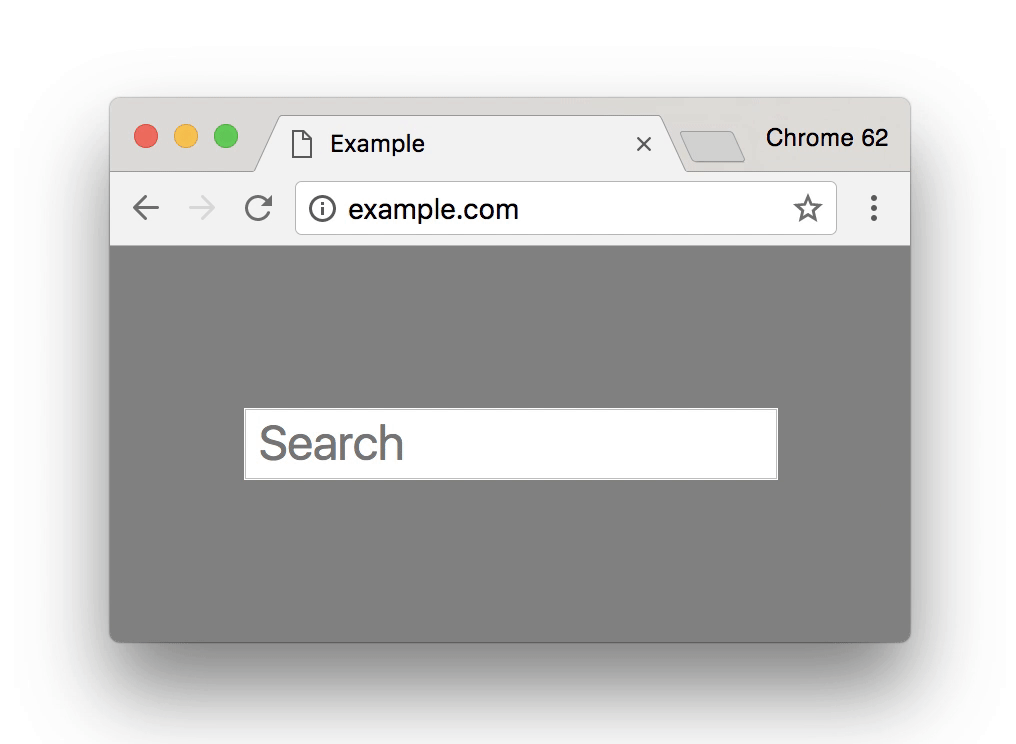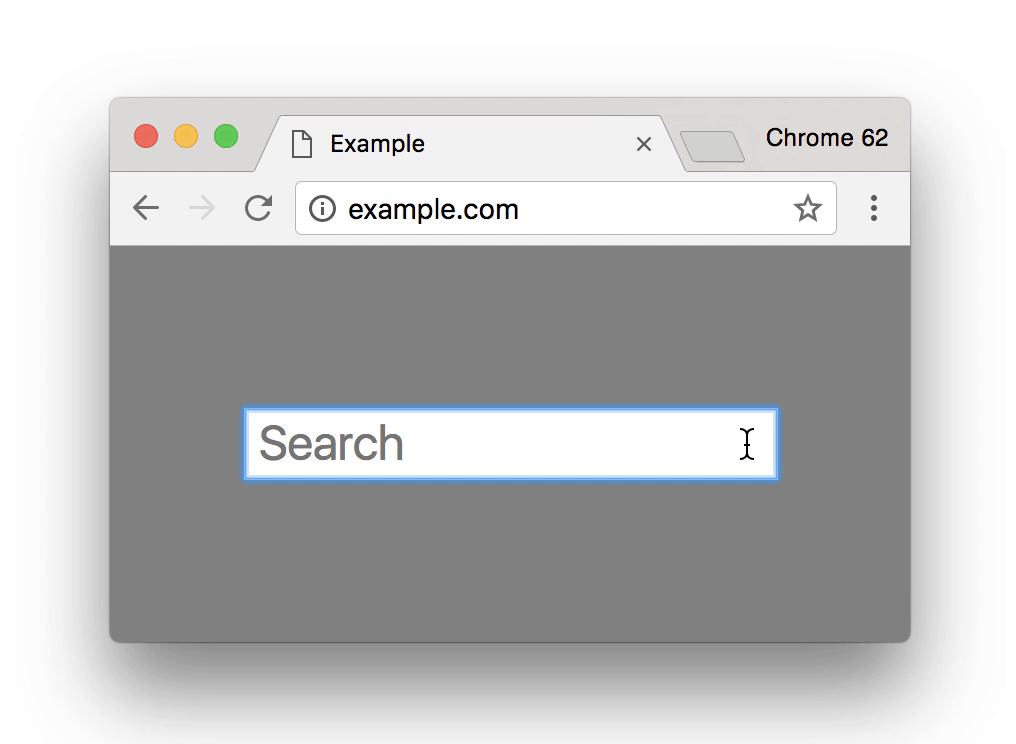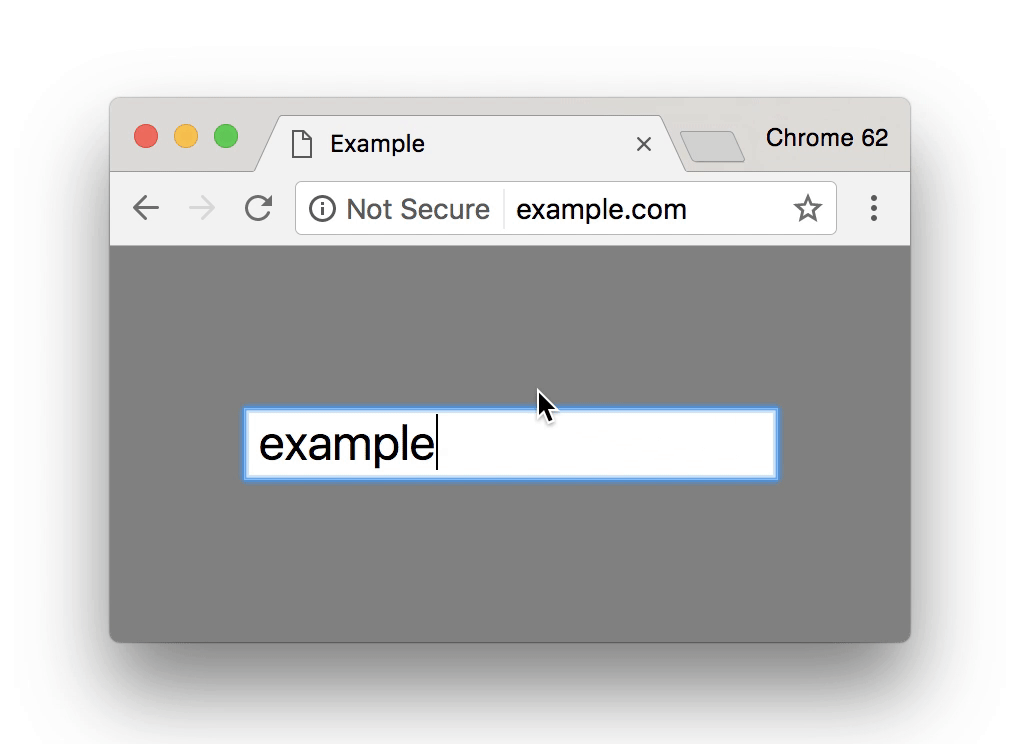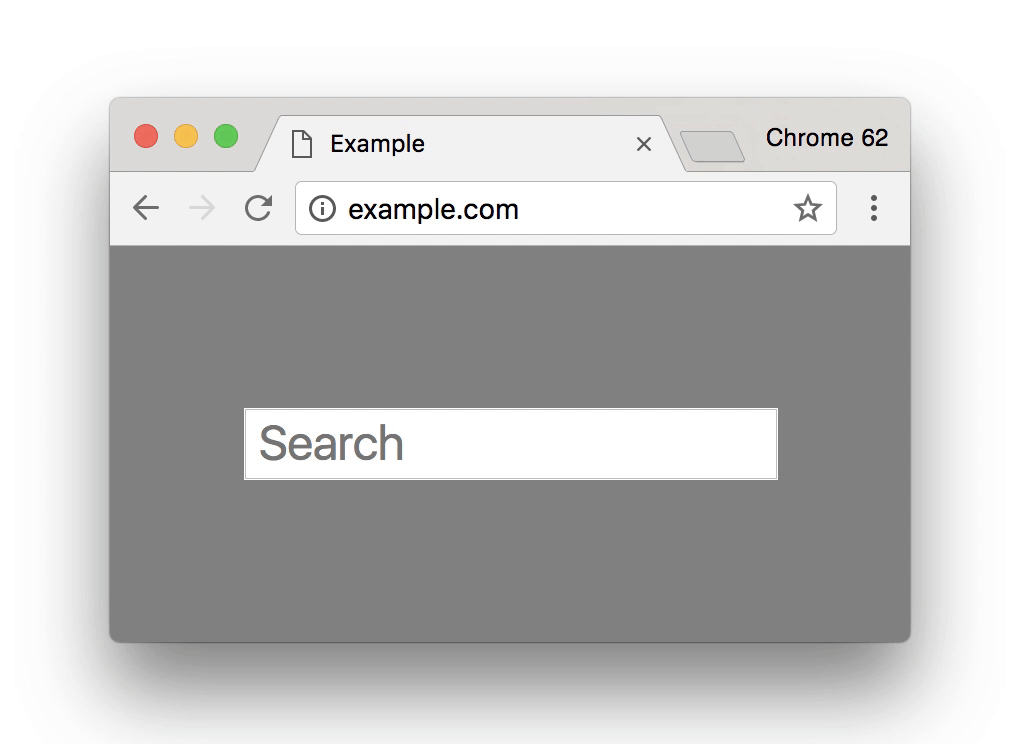
Today there is absolutely zero reason for an IoT (or router) developer or vendor to embrace HTTPS when all it will bring them is an endless stream of complaints from grumpy users (at best) and frantic emails from hyperventilating less-tech-savvy clients that think their smart lightbulb has been hacked by Russian spies, when all they have to do to avoid that situtaion is not use HTTPS and stick to insecure HTTP for the foreseeable future.
In fact, the only way workaround for this for a lan-only device that is not internet accessible but still wants security on the intranet – remember that non-public TLDs like .lan or .local are forbidden from obtaining SSL certificates – is to obtain a certificate for some website https://example.com/ and, after obtaining said certificate, modify its DNS settings so that it points to an internal IP (where a copy of the certificate is installed), a process by means of which the owner of the domain example.com can prove their ownership to the CA and then make the decision to redirect it to an internal resource. Or expose their IoT device on the internet and have it negotiate a self-signed certificate for itself via LetsEncrypt or similar instead of keeping it securely behind the firewall where it belongs. Either way, it’s broken.
In summary, there’s no compelling reason to keep the security interstitial when visiting HTTPS resources presenting self-signed certificates on intranet IP addresses. If you’re not yet convinced of the importance of the matter, put aside consumer electronics and IoT devices and look at corporate networks instead. A subnet like 10.0.0.0/24 can host 224 devices on the same network. Certainly it is imperative to streamline the process of securing requests internal to such a network, even if they are not accessible from outside the internet and not eligible for a CA-signed certificate from one of the recognized/whitelisted certificate authorities?
It’s ironic that – from the very start – in the pursuit of “security” browser vendors (all of them) have consistently treated HTTPS resources presenting self-signed SSL certificates as inferior to plaintext HTTP connections, and here we are some 20 years after the initial release of Internet Explorer 5.0b1 in June of 1998 still punishing those that try to secure their content as best as they are able.
While the discussion of how to treat self-signed HTTPS requests over the web has been hashed to death over the years, the question of how to present such requests when the server in question is identified by a private IP on the intranet is hopefully a lot more clear-cut and more of an oversight than a purposeful decision. The fact that most recent/soon-to-be-released versions of major browsers will not present a security warning for the local loopback address 127.0.0.1 aka localhost when served over HTTPS with a self-signed certificate gives us some hope that perhaps CA/B or at least just browser vendors will realize the importance of making HTTPS accessible for everyone – IoT and intranet devices included – and hopefully no longer punish those that do literally all they are permitted to secure the servers under their control.
Source: BuiltWith SSL trends ↩
OK, maybe I’m exaggerating.. a little. ↩
How about we fix the web browsers to understand the difference between signed, unsigned, and non-HTTPS connections? There is no reason to not use HTTPS. This isn’t a vendor problem, it’s a web browser problem. This article is very bad practice.
Zack said:
> This isn’t a vendor problem, it’s a web browser problem.
I think the article means “the guys that make web browsers” when it says vendor.
Unless you meant vendor as in “the people making IoT devices”?
typo: 10.0.0.0/8 can host 224
10.0.0.0/8 can host 2^24
I’ve ran into this extensively with mDNS addresses.
My proposal to solve this is for browsers to trust-on-first-use any certificate on .local, .home.arpa and RFC1918/v6-equivalent addresses, and linking it with any pinned certificate if HPKP is in use.
If a conflicting certificate shows up (or just a new one after the original one has expired), the browser could then show a warning (not blood-death style) to the user, offering to refuse the connection, or to accept the certificate as a follow-up, or to accept the certificate but treat it as a new origin (thereby dropping all stored credentials/cookies etc for that domain).
I’ve proposed this before in Mozilla’s flyweb group at , but I’d be happy to take up the discussion anywhere else where it could be more fruitful.
Oups, that link got swallowed because I put it in angular brackets; previous discussion is on https://groups.google.com/forum/#!topic/mozilla.dev.flyweb/HZtm2qA2oU4 .
Let’s stop talking about these nasty “IoT” spyware devices altogether, shall we?
@chrysn you mean like SSH has done for decades?
This is completely ill-informed. Any attacker can inject and eavesdrop into connections “secured” by self-signed SSL (TLS) certificates. All the attacker has to do is produce his/her own forged certificate and the client will be none the wiser. If certificate authorities started signing certs for local IP addresses, then anyone and their mother could get a “signed” cert for 192.168.1.200, and so attackers could still man-in-the-middle these connections. There is no good path forward for securing these devices without using unique identifiers for devices, like domain names.
Private TLDs are also unsuitable for certificates because no one can claim sole ownership of an unregistered name. Also if every device of a specific model (e.g. all Samsung smart fridges or what-have-you) uses the same private key, an attacker may be able to extract it from the device and then MITM any connection from anyone else’s device of the same model.
To truly secure IOT devices on the intranet it would be necessary to develop a new method where devices are shipped with unique fully-signed certificates that are each registered with unique domain names by the manufacturer. These domain names could be printed on the device, letting each user connect to his or her smart fridge and have the connection be fully verified by a chain of trust.
The reason browsers present these warnings is because your connection is truly no more secure with HTTPS than with plain HTTP unless the chain of trust can be verified. Many browsers are moving to deprecate HTTP, and rightfully so.
At least HTTPS would encrypt the data, that would protect against trivial spying. It has been proposed for TLS 1.3 to get Opportunistic encryption that would do exactly that.
I am surprised that so few articles, like this one, talk about this issue. I cannot see any “good” solution yet.
Having the manufacturer handling the certificate is nice and original, but users would have to manage their local DNS?
Also what about IPv6 … I don’t think that browsers alone will solve the issue. I guess that routers ADSL boxes and so on will have to play a role
@Arjun Govindjee while I get where you are coming from, I think you are missing the argument the author is making.
“Any attacker can inject and eavesdrop into connections “secured” by self-signed SSL (TLS) certificates.”
Yes — any attacker with the capability to actively intercept and modify traffic can do this. If this is the situation on your LAN, I feel like you have bigger problems than someone manipulating the TLS connection to your smartfridge.
“There is no good path forward for securing these devices without using unique identifiers for devices, like domain names.”
It is true that you really cannot have fully authenticated TLS communication without devices having some unique identifiers which can also be uniquely tied to the device. It does not mean that there is no path forward. There are other mechanisms of establishing trust. For example, the known_hosts approach taken by SSH or the first time certificate trust model employed by firefox (i.e. the certificate exceptions).
“To truly secure IOT devices on the intranet it would be necessary to develop a new method where devices are shipped with unique fully-signed certificates that are each registered with unique domain names by the manufacturer. ”
This is not exactly scalable in the real world. For starters, who is going to manage the DNS records for these domain names? Are you thinking the certificates can be generated, signed, and installed onto ROM in the factory? There are a lot of challenges in this approach starting with what to do when the certificate expires. They key material also needs to survive factory resets. Having the devices request certs during the out of box experience is more practical in some ways but still comes with a lot of difficulty for the IoT vendors to get right. These are the same vendors who chronically ship devices with hardcoded passwords, blatant command injection and buffer overflows. Asking them to try and get something like this right is a nightmare and would only lead to a really unpleasant user experience.
“The reason browsers present these warnings is because your connection is truly no more secure with HTTPS than with plain HTTP unless the chain of trust can be verified. ”
This is wholly untrue. HTTPS with a self-signed certificate still protects against passive attackers whereas plaintext transmission protects against nothing.
Great. We will have to do something about https.
Hello,
Craig Young said: “Yes — any attacker with the capability to actively intercept and modify traffic can do this. If this is the situation on your LAN, I feel like you have bigger problems than someone manipulating the TLS connection to your smartfridge.”
In my small home environment I would agree with you. But what about my company LAN with dozens or hundreds of tech personal? Should I trust anyone of them like my brother?
Chances that hidden wire taps are found here are small and there are a lot of attack vectors in huge company LANs.
Bigger organizations could afford to run their own internal CA and deploy their root certificates to all of their client devices. And they should do that instead of saying: “Oh hey, it’s from a local domain or RFC 1918 ip address, let’s trust the connection, it’s all for good.”
As an alternative of running your own CA you could published the self signed certificates you are using in your LAN on your intranet. So your internal clients have a cross reference they could check.
For the IoT trash floating the marked I would suggest a solution like this:
Deliver IoT devices with self-signed certificates and print the properties from the self-signed cert to the box or onto the chassis of the IoT itself. Make it easier for the customer to check whether the information from the certificate shown in his browser are the same as on his device. So he could check and accept the certificate all for good. This won’t work for huge company LANs where you have no idea where your device is placed. But these organizations should use their own CAs to solve this problem.
For me, I don’t care if a certificate is self-signed or not if I could check if it is the certificate that should be on this device. Besides following Ivan Ristic the internet pki is broken for years now. Why should I trust a cert from my browsers trust store more than a self signed in general?
In the end I agree that IoT and SOHO devices needs mechanisms to check if the self signed cert is the one it should be. And for RFC 1918 ips and local domains the browser warning could be less harsh and should encourage the user to check the certificate instead of scaring him.
Best regards,
Joerg
Hi Joerg,
Responding to your remarks:
“In my small home environment I would agree with you. But what about my company LAN with dozens or hundreds of tech personal? Should I trust anyone of them like my brother?”
I’m unclear about why you think this is an argument to use plaintext HTTP over HTTPS with self-signed certificates but…
In your company LAN, I would hope that you are on a switched network with protections against ARP poisoning to mitigate many risks of MiTM. If that is not the case, the organization can still get a certificate either signed by a public trusted CA or from an internal CA that they extend trust to on workstations. This change has no impact on anyone’s ability to get SSL with trusted certs. (The device can still operate on a private address space as long as DNS servers tell clients the correct address.)
“Bigger organizations could afford to run their own internal CA and deploy their root certificates to all of their client devices. And they should do that instead of saying: “Oh hey, it’s from a local domain or RFC 1918 ip address, let’s trust the connection, it’s all for good.”
Looks like you may not be getting this clearly. Nothing proposed in this article would prohibit or impede anyone who wants to get a certificate for their devices. Running an internal CA costs only as much as any other computer. There is no special sauce or hidden costs limiting it to big firms. The trick is that the certificates should be bound to domain names (like most certificates) and users should access the devices via domain name. A certificate bound to a private IP address is essentially as worthless as a self-signed certificate anyway since nobody can prove or claim sole control over the address as they can with a domain name.
“Deliver IoT devices with self-signed certificates and print the properties from the self-signed cert to the box or onto the chassis of the IoT itself.”
First of all, it is not as easy as you would think to generate a unique self-signed cert in the factory and have it stored on products in a way that would be persistent across software upgrades and device resets. Second, what exactly do you think they are going to print on the label? A certificate fingerprint? A public key? Do you really think this helps anything? Who do you expect to check these values to manually authenticate the connections? Many times these connections are happening within apps anyway where the user has no view of the certificates.
“Make it easier for the customer to check whether the information from the certificate shown in his browser are the same as on his device.”
Have you used Chrome recently? They have obscured this information into the developer tools. Firefox is also not perfect either with several clicks required to really get identifying details.
“So he could check and accept the certificate all for good. This won’t work for huge company LANs where you have no idea where your device is placed. But these organizations should use their own CAs to solve this problem.”
This really doesn’t work for a home environment in any meaningful way since virtually nobody is going to check the data. Furthermore this process you have described could considerably complicate device manufacture.
“Why should I trust a cert from my browsers trust store more than a self signed in general?”
Because the list of trusted certificate authorities participate in CA/B and must meet the baseline requirements including things like CT and CAA to provide additional levels of authentication.
Without a doubt, the PKI system we use is very fragile but this is really completely besides the point of this article.
To reiterate, the point of this article is that currently IoT vendors are motivated to not employ any HTTPS because it only leads to user experience complaints. I personally think that an appropriate measure would be that if a user enters a private IP address into the browser address bar or opens a bookmark, they can be presented with an insecure notice similar to the one Chrome will deploy for HTTP. The certificate details can then be stored associated with any available identifying information about the network. (For example SSID details or the mac addr of the default gateway.) If the browser ever encounters a different certificate coming from the same IP/port/network context it should show a full interstitial page informing the user that the remote certificate has changed and advising that this would be the case if the device was reset as well as if someone is launching an active attack.
Hi Craig,
Indeed it seems that I didn’t get the point of the article. Of course I wouldn’t choose HTTP connections over HTTPS whether self signed certificates are used or ‘trusted’ ones. But indeed I understood that the idea of this article is that browsers should not show a warning message when accessing a device over HTTPS on local LAN via IP address or something like domain.local.
Thank you for the clarification. So the idea is how to make it happen that implementing and using HTTPS is sexy and HTTP is going to be the old and dirty crap from the past?
I have to admit the short notice in chromium that the HTTP login page of my NAS is not secure is pretty lame. But in firefox I got a straight and clear warning in each field of the form. So at first all browser should show a big fat red warning on a HTTP login page. Because the first page would usually be a login page. Do you agree?
But what to do with the big red warnings about self signed certificates? Whether to show a red warning or a green lock most user agents decides whether they could verify the chain of trust or not. So today all self signed certs or those form a CA not in the trust store will get the red warning.
If I got the idea of the article right, now. The author suggests to show a different warning when the common name or subject alternative name of some certificate shows only local domain names like domain.local or private IP addresses?
In that case I would agree that instead of a warning like “Alert, Warning, Death and Destruction ahead!” a more sophisticated message like “Caution, the validity of the certificate could not be verified, but it is from a local IP address or local domain. So it might be ok, either”.
But does this help a user to decide whether it is safe to use this connection or not? Will this prevent developers from creating HTTP accessible management UI for their devices?
Most users just type in the IP address or the hostname of their device. All browsers try to establish the connection via HTTP first. Current versions use HTTPS instead if they found such a connection in the browser history. I would like the browsers would at first try to establish the connection via HTTPS instead of HTTP. This way the user connects to the secure page first and do not have to think about the protocol to use. Developers and SysAdmins could prevent connections errors in implementing HTTPS access.
When you are about to connect to the HTTPS service and get a warning from your browser I would like to be able to check whether the self signed certificate belongs to the device or not. The question is how could this be done? Is there any better way instead in showing a softer warning?
Best regards,
Joerg
“If this is the situation on your LAN, I feel like you have bigger problems than someone manipulating the TLS connection to your smartfridge.”
It is the situation of the user of a laptop computer who connects it both to a home LAN and to a coffee shop hotspot. Any active attacker in the coffee shop can impersonate the user’s home server.
“Running an internal CA costs only as much as any other computer. There is no special sauce or hidden costs limiting it to big firms.”
You need a computer that is always turned on to handle the OCSP responses. You also need a computer that is always turned on to handle split-horizon DNS for the internal hostnames. The ISP-provided modem/router device that connects a home LAN to the Internet may not have these features.
Seems like the best option for a home user is to get real IPv6 addressing, a real domain, real dns, and let’s encrypt certificates. Unfortunately, some IoT may not support RA addressing.
@Joe that opens up your attack surface considerably. Having a completely isolated LAN (or view of the LAN) is much more secure.