 NeoSmart Technologies is pleased to announce the immediate availability of its open source
NeoSmart Technologies is pleased to announce the immediate availability of its open source NeoSmart.Collections library/package of specialized containers and collections designed to eke out performance beyond that which is available in typical libraries and frameworks, by purposely optimizing for specific (common!) use cases at the cost of pretty much everything else.
In many regards, the data structures/containers/collections that ship with pretty much any given framework or standard library are a study in compromise. Language and framework developers have no idea what sort of data users will throw at their collections, or in what order. They have no clue whether or not a malicious third party would ultimately be at liberty to insert carefully crafted values into a container, or even what the general ratio of reads to writes would look like. The shipped code must be resilient, fairly performant, free of any obvious pathological cases with catastrophic memory or computation complexities, and above all, dependable.
It isn’t just language and framework developers that are forced to make choices that don’t necessarily align with your own use case. Even when attempting to identify what alternative data structure you could write up and use for your needs, you’ll often be presented with theoretical 𝒪 numbers that don’t necessarily apply or even have any relevance at all in the real world. An algorithm thrown out the window for having a horrible 𝒪 in Algorithms and Data Structures 101 may very well be your best friend if you can reasonably confine it to a certain subset of conditions or input values – and that’s without delving into processor instruction pipelines, execution units, spatial and temporal data locality, branch prediction, or SIMD processing.
Continue reading →

 Easy Window Switcher, our Windows “power toy” that brings macOS-like switching between open windows of the same application with Alt+` to Microsoft Windows, has just been updated to version 1.3.0. This new release brings some much requested fixes for keyboard layouts used by our friends in Denmark and Sweden and some more compatibility fixes for everyone else.
Easy Window Switcher, our Windows “power toy” that brings macOS-like switching between open windows of the same application with Alt+` to Microsoft Windows, has just been updated to version 1.3.0. This new release brings some much requested fixes for keyboard layouts used by our friends in Denmark and Sweden and some more compatibility fixes for everyone else.
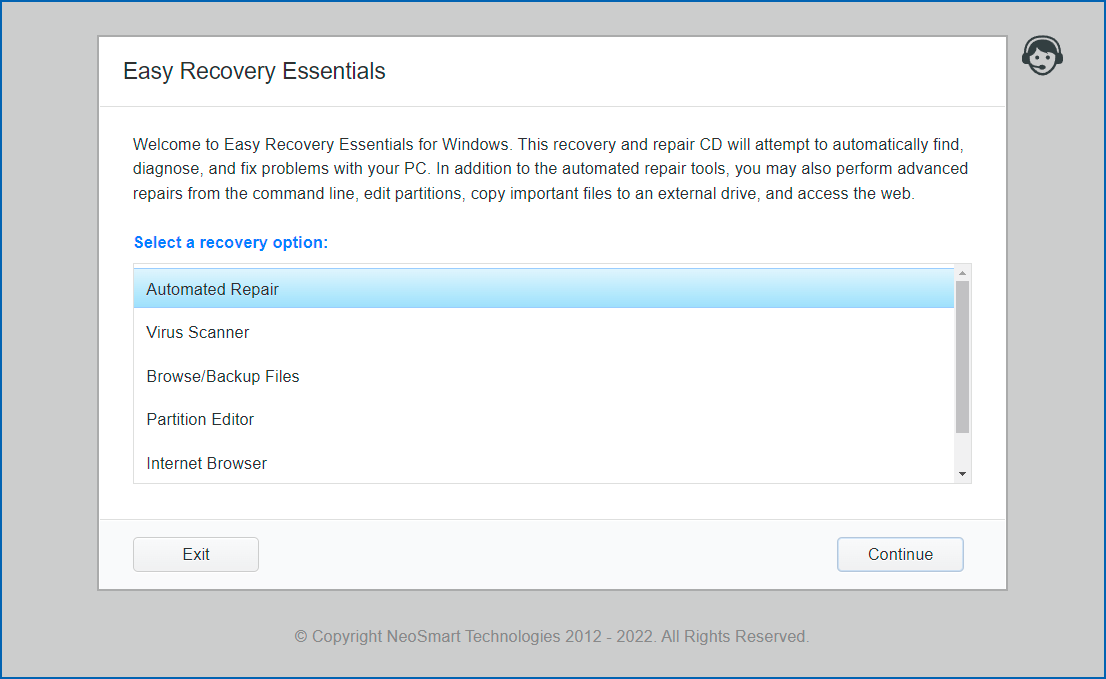




 We are proud to present the latest addition to our open source portfolio,
We are proud to present the latest addition to our open source portfolio,